Making Globally Distributed Systems easier with Leadership elections in .NetCore
Recently I’ve been looking at how to ensure services are always running globally across a number of data centres.
Why would you want to using Leadership elections to do this?
I’ll cover this at a very high level, for more detail look at articles like this, this I also highly recommend the chapter covering this in Google’s Site Reliability Engineering boo k.
I want the service to remain available during outages which affecting a particular node or DC.
To do this you have two options, active-active services, where all DC’s can serve all traffic, or active-passive, where one DC or Node is a master and the others are secondary’s. There is also a halfway house but we’ll leave that for now.
The active-active example is better for some scenarios but comes at a cost, data replication, race conditions and synchronisation require careful thought and management.
For a lot of services the idea of a master node can greatly simplify matters. If you have a cluster of 3 machines spread across 3 DCs and they consistently elect a single, healthy, master node which orchestrates requests - things can get nice and simple. You always have 1 node running as the master and it moves around as needed, in response it issues.
The code it runs can be written in a much simpler fashion (generally speaking). You will only ever have one node executing it, as the elected master, so concurrency concerns are removed. The master can be used to orchestrate what the secondaries are doing or simple process requests itself and only use a secondary if it fails. Developers can write, and more importantly test, in a more managable way.
Now how does this affect scaling a service? Well you can now partition to scale this approach. When your single master is getting top hot you can now split the load across two clusters. Each responsible for a partition, say split by user id. But we’ll leave this for another day.
So how do we do this in .Net?
Well we need a consensus system to handle the election. I chose to use an etcd cluster deployed in multiple DCs, others to consider are Consul and Zookeeper. Lets get into the code..
ETCD is used to hold data on who is the master node and other important data, like how to talk to it and which partition is being handled by which node. Etcd uses raft, kinda like Paxos, to ensure all Nodes get the same view of the data (there are some nuances here, see the writeup here, but this can be managed when understood). You can read more about ETCD here, for now we’ll move onto how I used it to elect a master node.
To avoid churn of the master (it switching around lots between the nodes) I’ve used an approach which favours electing the longest running node as the master. Each of nodes starts up and get an “in ordered key”. For example: node 1 gets Key:1 node 2 gets Key:2 ….
Each node then retrieves all the keys, in ascending order, and checks if it’s the top of the list. If the node is at the top of the list it’s the master, simple!
The keys have a TTL (time-to-live) which ensures that, should the master node hang or be destroyed, the next node in the list will be elected as the master.
Here is a simple, if slight naive, implementation. (I’ve favoured clarity over robustness here to help illustrate the approach so you’d likely need to change things to run a production workload.)
One thing to note with this approach is that a master node, upon discovering it’s no longer master, is responsible for stopping behaving as a master. In the GitHub repo, a slightly more advanced version, I use a cancellation token to handle this transition.
https://github.com/lawrencegripper/dotNetCoreLeaderElection
Lastly here is it up and running, a local test instance of etcd running with two nodes connected and participating in an election.
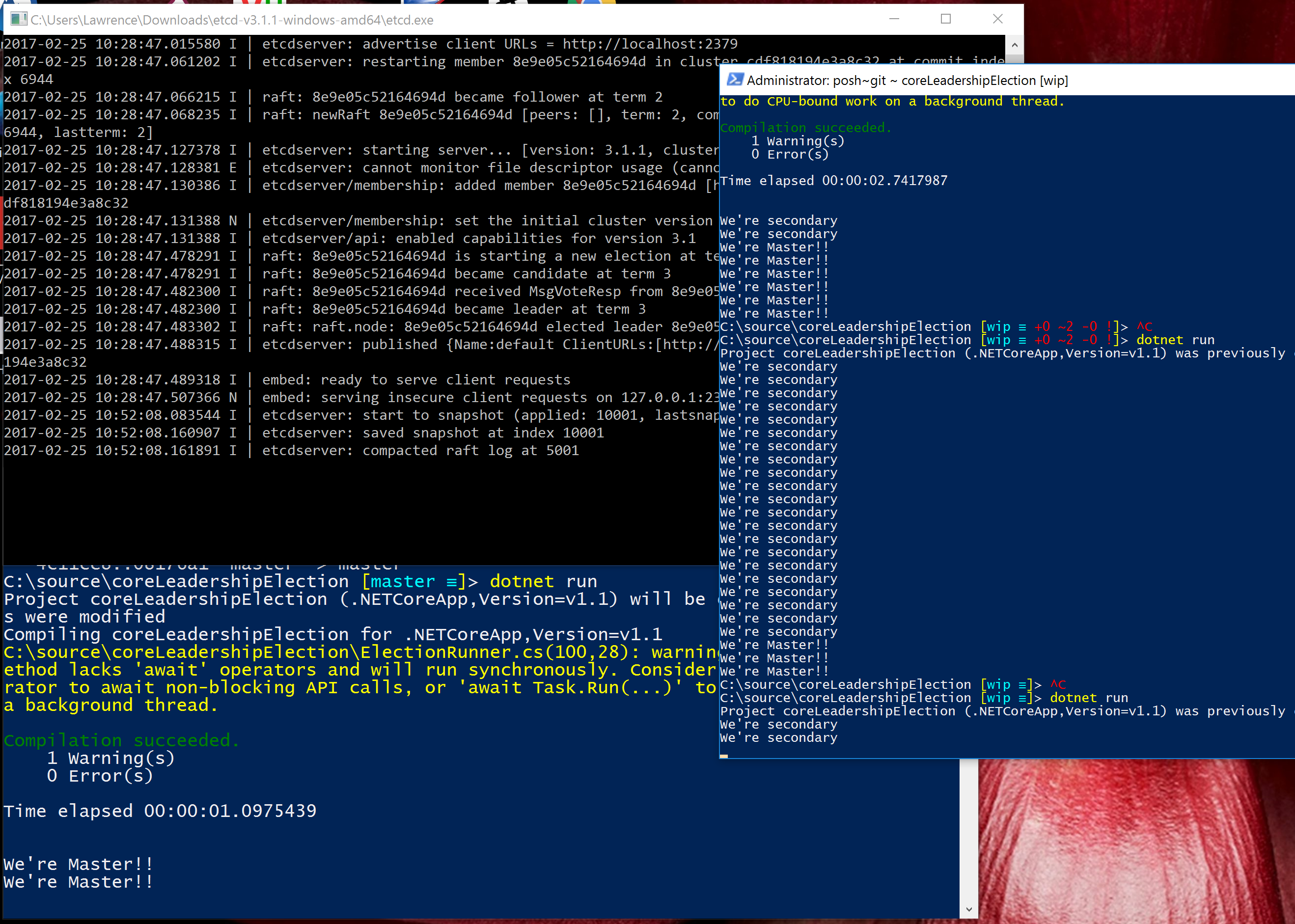
Next up: I’d like to write a distributed lock using ETCD for .NetCore which allows you to using TPL to wait on a named lock - eg await EtcLock(“someSharedResource”). This would allow finer grained control accross nodes, rather than master and secondaries, nodes could take locks as needed on shared resources. There are dangers here but I’m interested to explore it further and see where it take me!