Using .img files on Azure Files to get full Linux filesystem compatibility
Here is the scenario, I wanted to use a container to run a linux app in Azure and I need to persist changes to the filesystem via Azure Files. This, initially, appears to be nice and simple - you mount the Azure File share using CIFS and then pass this into docker as a volume mount. But what if you app relies on some linux specific operations some, like symlinks, can be emulated see here for details, but others can’t.
This is a really simple little hack which I learnt from the Azure Cloudshell implementation. It uses the ‘.img’ format to store a full EXT2 filesystem on Azure files.
How does it work? Well if you open a cloudshell instance and use the ‘mount’ command you can see it has two mounts, one for CIFS and one for a loop0.
[gallery ids=“1052,886” type=“rectangular”]
Seeing this started to peak my interest, what was the loop0 device mounting as my home directory? The cloudshell creates a storage account to persist your files between sessions, next I took a look at this to see what I could find.
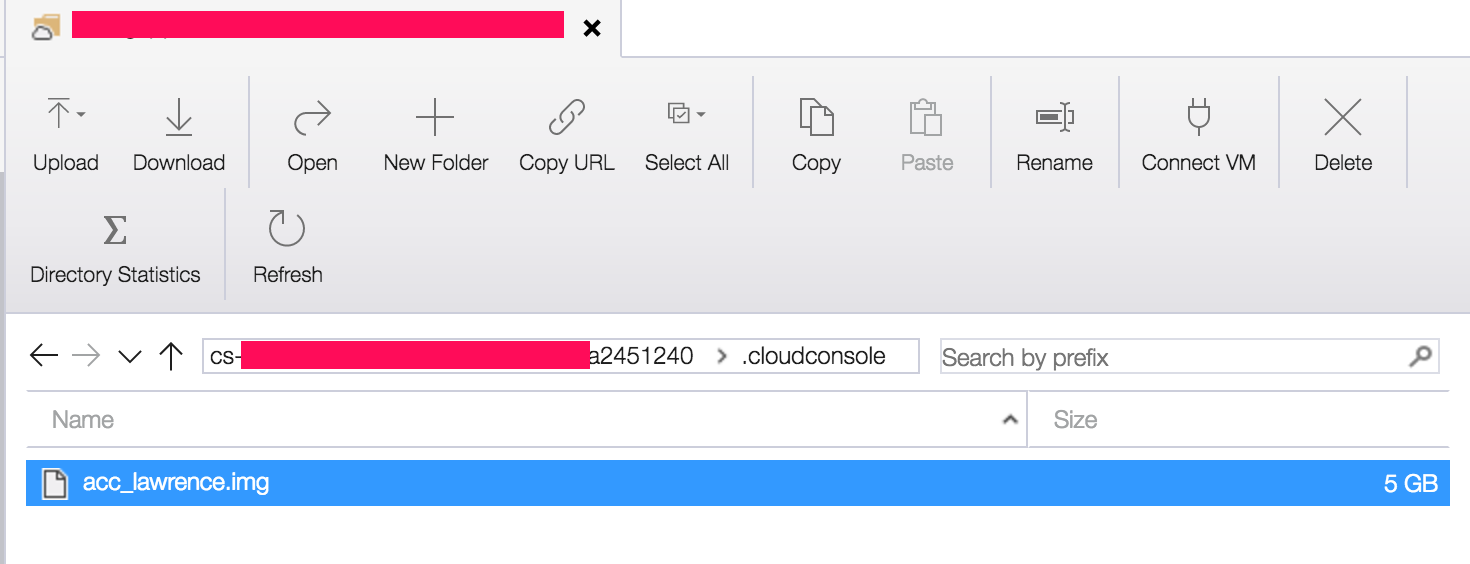
This is when I found the ‘.img’ file being used. So how do we use this approach for ourselves, as it seems to work nicely for cloudshell?
It’s actually pretty simple, we mount the Azure file share with CIFS, create the ‘.img’ file in the CIFS share, format it and then mount the ‘.img’ file. Done.
https://gist.github.com/lawrencegripper/33f28019c11bfd5188fe9df0a730038d
The key is to create a ‘img’ file which is sparse, meaning we don’t write all the empty space to file storage, otherwise creating a 10Gig ‘img’ file involves copying 10gig to Azure files. This is done by passing in the ‘seek’ command into dd on like 15.
So this gives you a fully compatible Linux disk stored on Azure files so it can persist container restarts and machine moves.
Ps. If you’re replicating super critical data dive this some extensive testing first, this approach worked nicely for my use case but do exercise caution.